
No Interference, No Ambiguity: The SUTVA Assumption
EP7: Causal Inference from the Ground Up

Randomization guarantees balanced, comparable groups. It does not guarantee that what you are comparing is well defined.

Consider an experiment on a referral programme. Users are randomly assigned to receive a referral link or not. The experiment looks clean — randomized groups, clear outcome. But referral programmes do not stay confined to individual users. User A gets a link, shares it with user B, and suddenly B’s outcome depends on A’s treatment. The experiment is contaminated.
The natural instinct is to fix this after the fact — adjust the model, add covariates, filter out the contaminated users. But as Fisher famously warned (Fisher, 1938)[1]:
To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination.
No amount of statistical adjustment will rescue a broken design. This is a violation of SUTVA — the Stable Unit Treatment Value Assumption — and it is the one I see violated most often in practice. When it breaks, you get confident numbers that mean nothing — you scale campaigns that never worked, or kill features that actually did.
Listen to This Episode
Want to dive deeper into SUTVA? This episode of the podcast walks through the intuition and practical implications of the assumption.
1. What SUTVA Requires
The causal effect for user i is
— the difference between what would happen with and without the referral link (for a full introduction to potential outcomes, see EP4).
But writing Yi(1) quietly assumes each user has exactly one potential outcome under treatment. For that to hold, two things must be true: user i’s outcome cannot depend on what treatment other users received (no interference), and “receiving the referral link” must mean the same thing for every user (consistency).
That is what SUTVA ensures (Rubin, 1980). When either component breaks, Yi(1) is no longer a single well-defined number — and neither is the causal effect.
2. No Interference
No interference requires that user i’s potential outcome depends only on their own treatment assignment, which can be written as
In our referral example, B’s potential outcome can no longer be written as Yb(tb) — it becomes
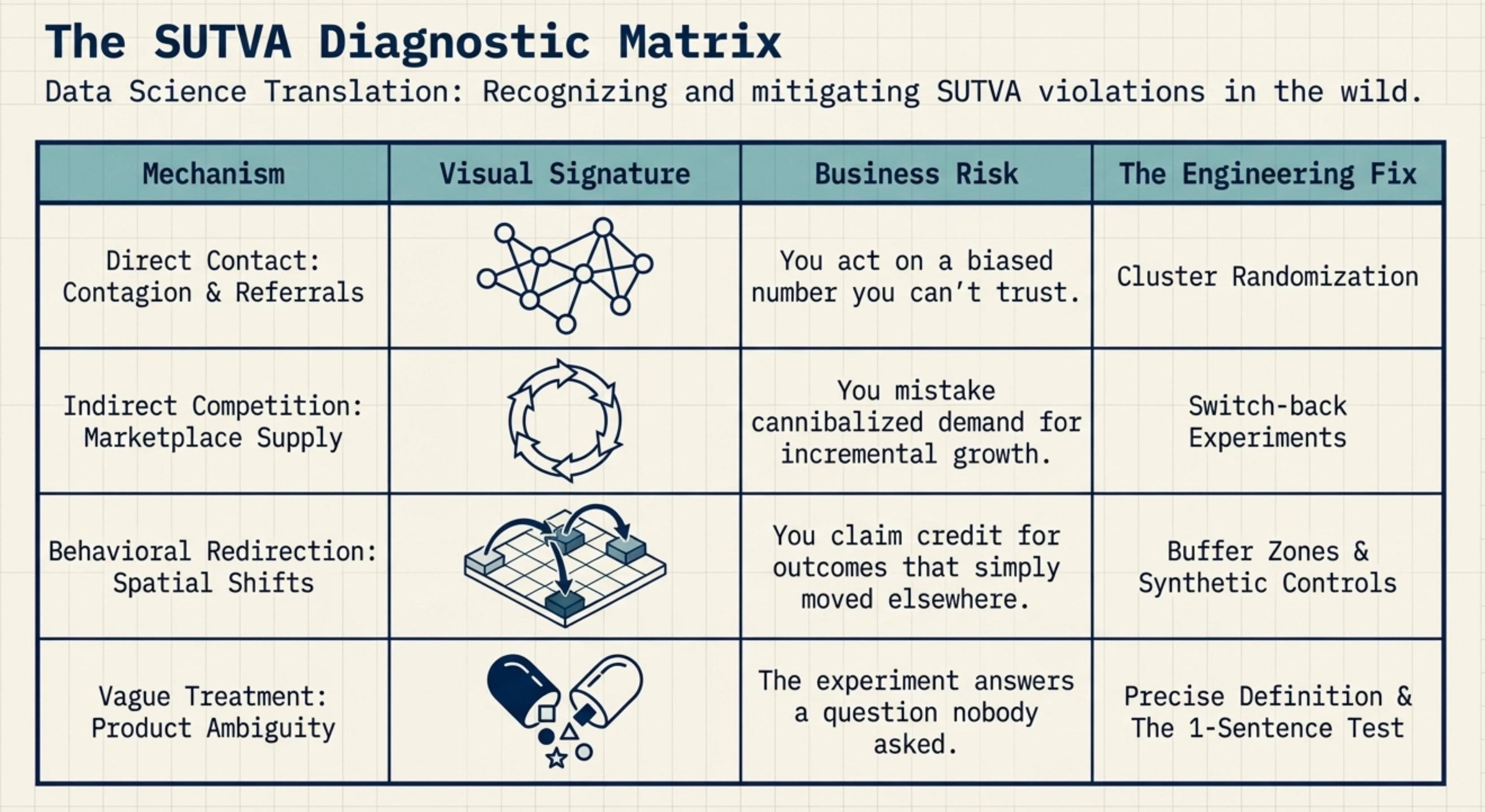
In practice, interference arises through three distinct pathways. Understanding which one applies determines how you fix it.
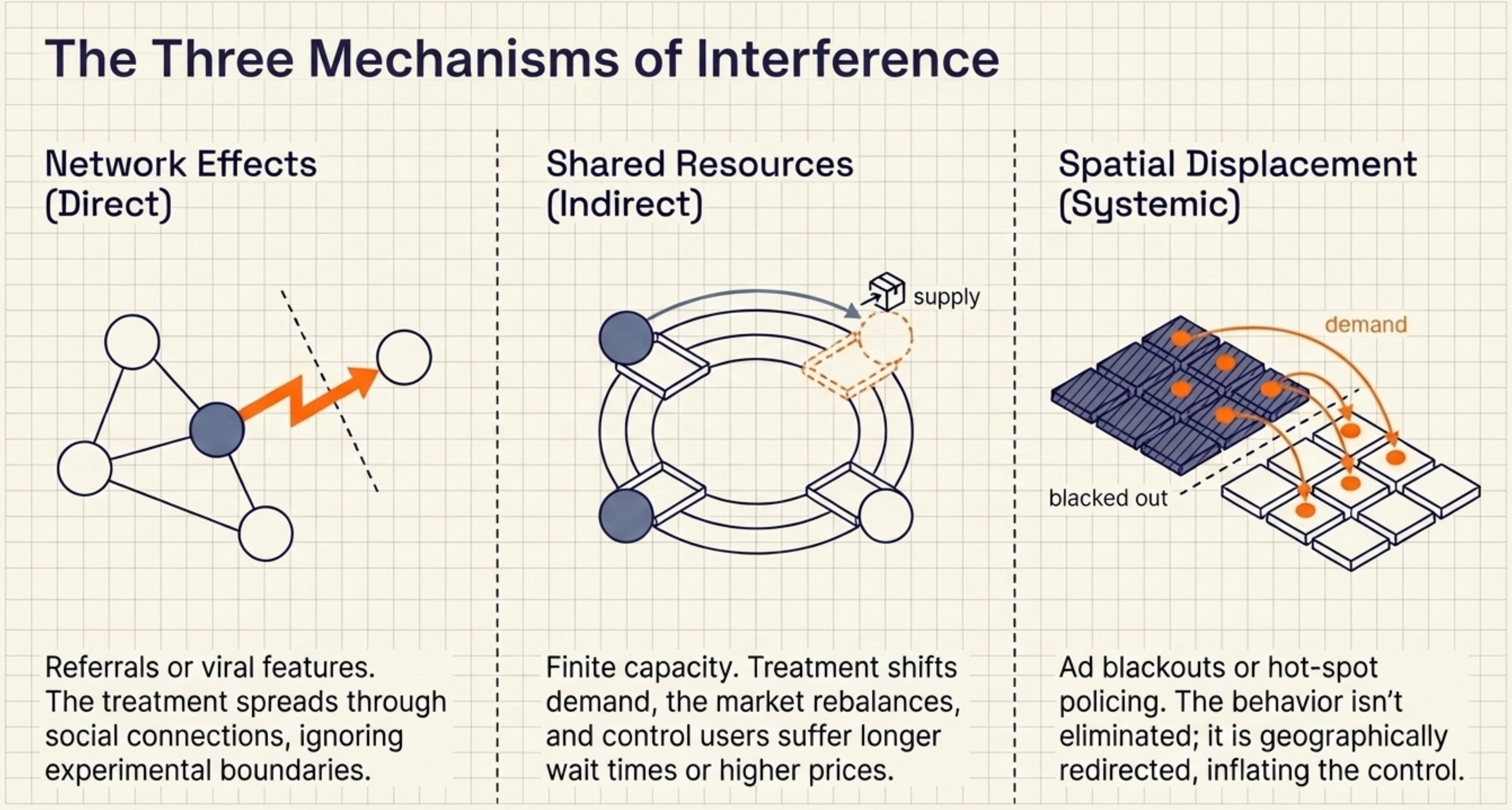
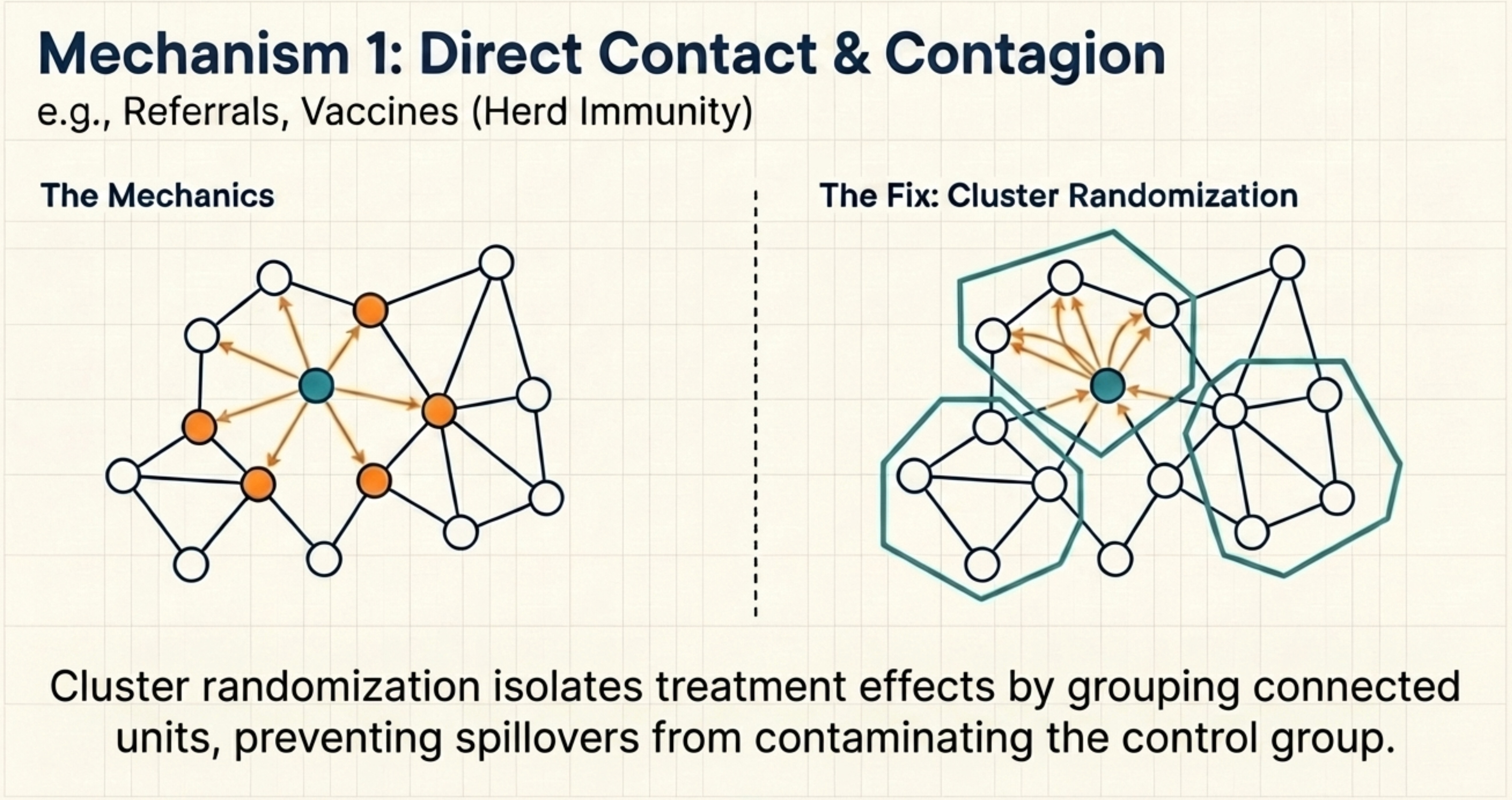
Direct Contact: Network Effects and Contagion
User A receives a referral link, shares it with friend B, and B’s behaviour changes — even if B was in the control group. The treatment spreads through social connections, not through the experimental design. The same happens in public health: vaccinating part of a population protects unvaccinated neighbours through herd immunity (Aronow & Samii, 2017; Halloran & Struchiner, 1995).
When one unit’s treatment directly changes another unit’s outcome through a network, the standard fix is to randomize at a higher level — cities or regions instead of individuals — so network interactions stay within the randomization unit (Toulis & Kao, 2013; Hudgens & Halloran, 2008). The trade-off: higher aggregation reduces statistical power, making it harder to detect small effects.
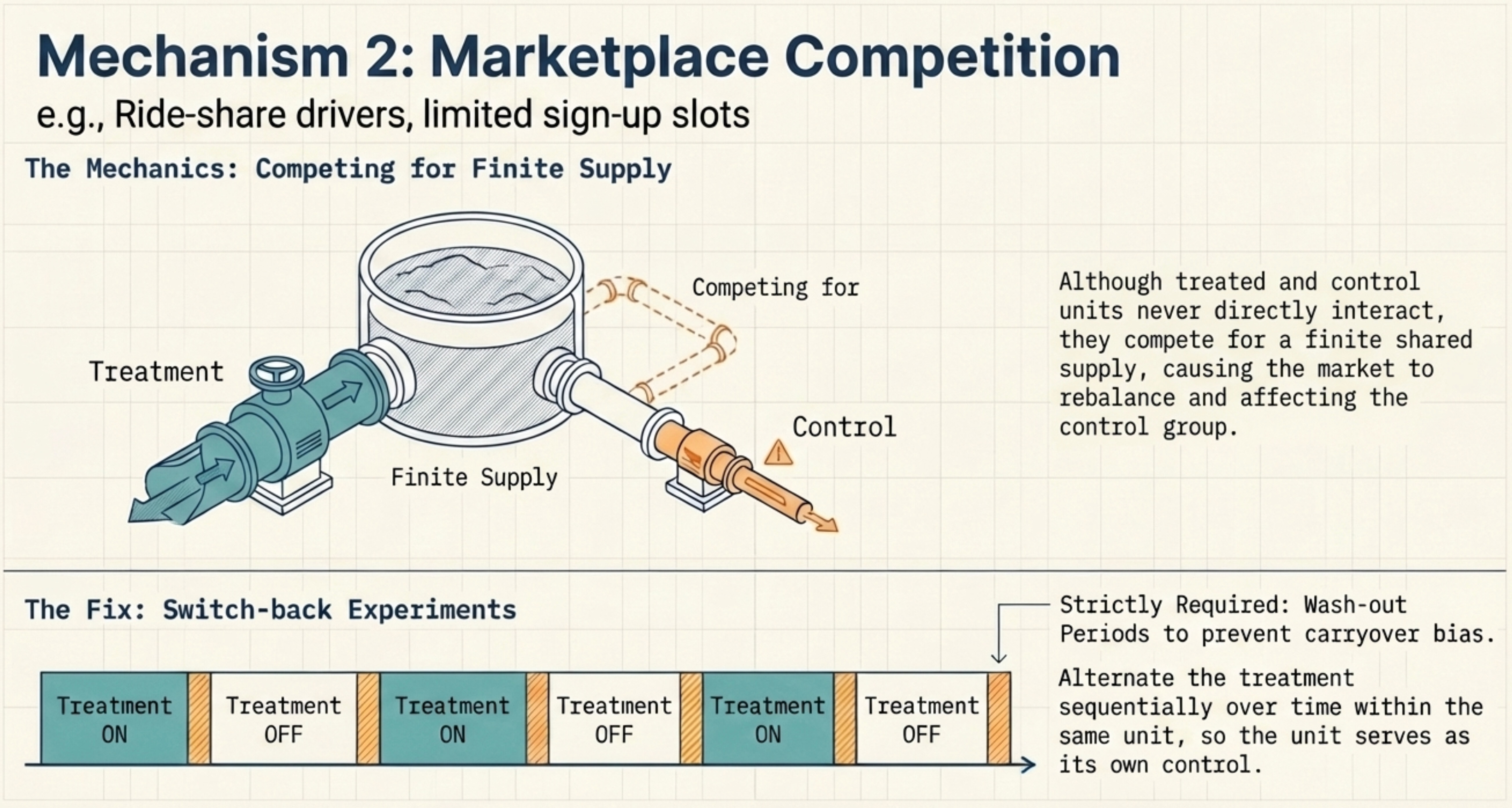
Indirect Competition: Shared Resources and Market Competition
Suppose our referral programme runs during a promotion with limited sign-up slots. A referred user claims a slot, fewer remain for non-referred users — even though the two never interact. The same pattern appears in two-sided marketplaces: riders competing for drivers, buyers competing for limited inventory. Treatment shifts demand, the market rebalances, and control users are affected through changes in availability, wait times, or prices (Blake et al., 2014; Johari et al., 2022; Holtz et al., 2024).
When units compete for finite supply rather than interacting directly, a common fix is switchback experiments — alternating treatments over time within a unit, so each unit serves as its own control (Crépon et al., 2013; Bojinov et al., 2023). The caveat: carryover effects between time windows can introduce bias, requiring wash-out periods in the design.
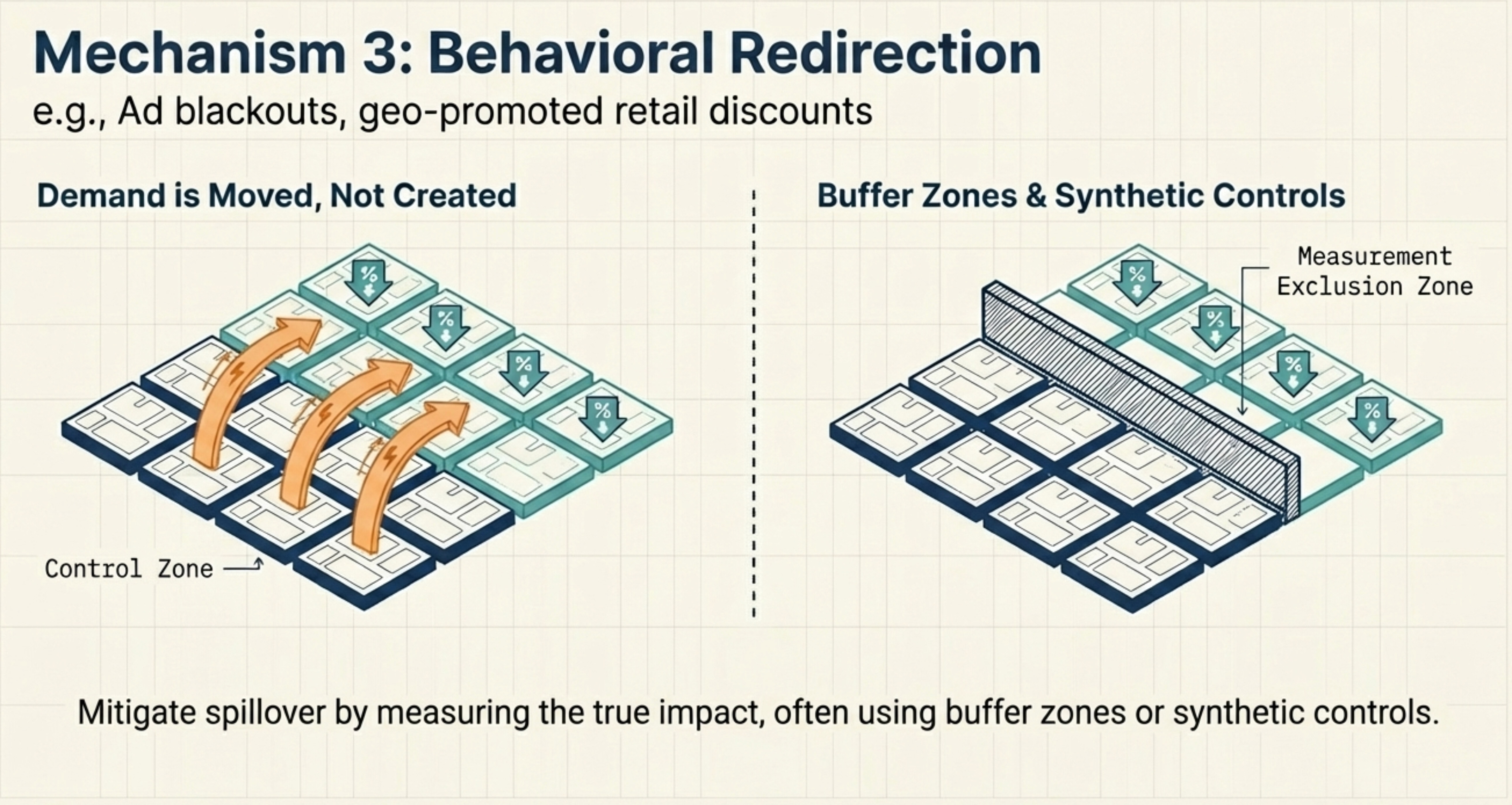
Behavioral Redirection: Spatial Displacement and Systemic Shifts
If our referral programme scales widely enough, word spreads that bonuses exist — and users who would have signed up organically start waiting for a referral link instead. The baseline shifts for everyone, not because of direct contact with treated users, but because the programme has changed expectations across the whole market (Sobel, 2006; Manski, 2013).
Now imagine a different promotion: a chain offers in-store discounts at randomly selected locations. Customers near non-discounted stores don’t stop shopping — some simply drive to a discounted store nearby. Demand spills over geographically, inflating outcomes at discounted locations and deflating them at control locations (Verbitsky-Savitz & Raudenbush, 2012).
When the intervention doesn’t eliminate a behaviour but moves it somewhere else, the fix depends on the type. For systemic shifts, a traditional A/B test fails by construction — the intervention changes the baseline for everyone. Instead, launch to an entire market and measure against a synthetic control: a weighted combination of similar unaffected markets that serves as the counterfactual. For spatial displacement, randomize at the level of naturally separated markets — e.g., different cities or countries — so geographic spillover between treatment and control is negligible. Where that’s not possible, exclude border areas from measurement to create a buffer between groups.
3. Consistency
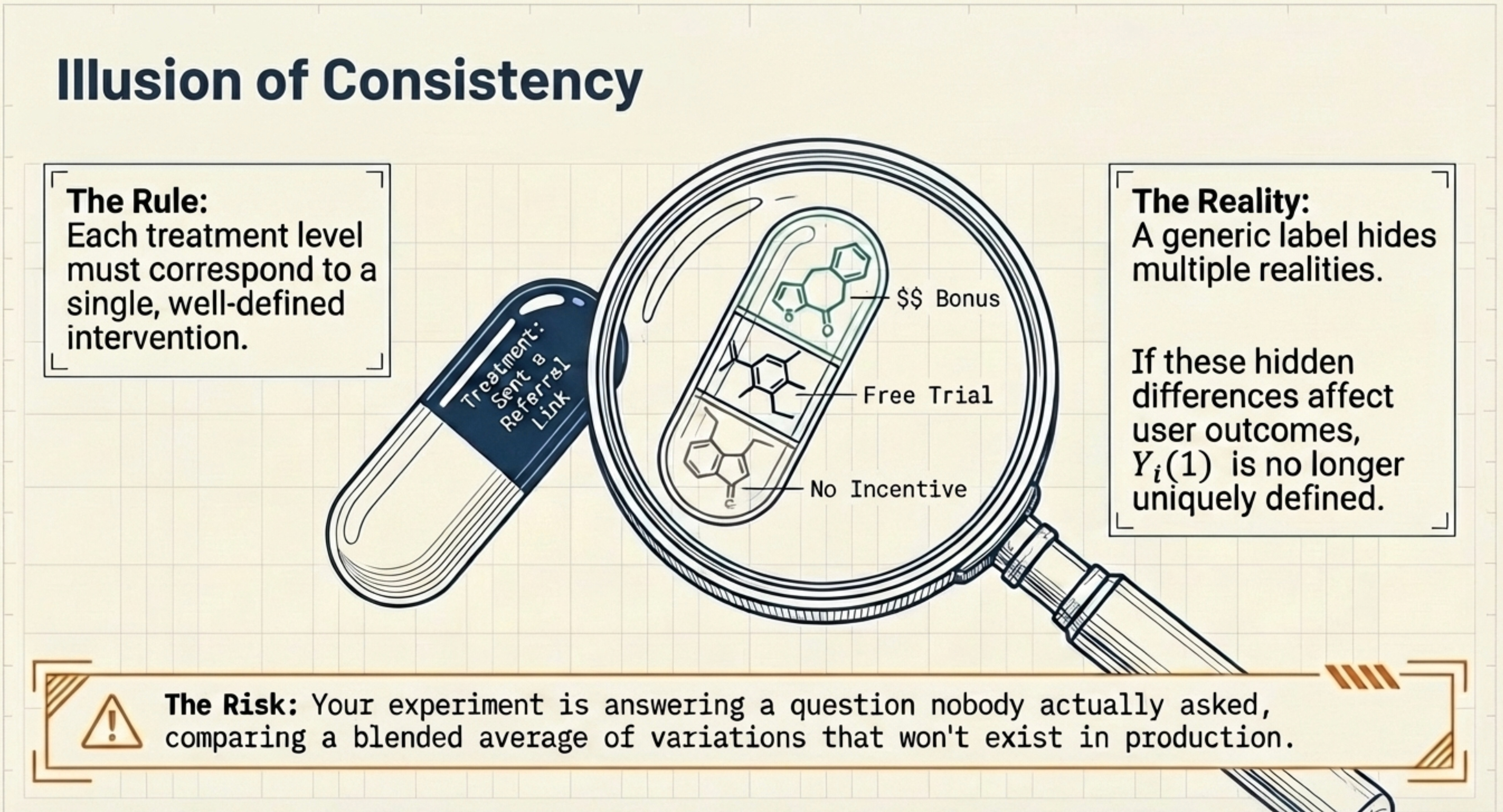
The second component of SUTVA is consistency: each treatment level must correspond to a single well-defined intervention.
At first glance this seems obvious. In practice, it is often violated.
Consider again the referral example. The treatment is defined as “sent a referral link.” But referrals may vary:
some include a monetary bonus
some offer a free trial
others contain no incentive
Two users assigned to treatment may therefore receive different interventions. If these differences affect outcomes, the potential outcome Y(1) is no longer uniquely defined. The treatment label hides multiple versions of the intervention.
As Hernán & Robins (2024) put it: “the more precisely we define the meaning of treatment T = 1 and T = 0, the more precise our causal questions are. We only need sufficiently well-defined interventions for which no meaningful vagueness remains.”
Consistency breaks in two ways: the treatment varies across users (some get a bonus, others get a free trial) or drifts over time (the incentive changes mid-experiment). Both are preventable — align with product and engineering on a precise treatment definition before the experiment is built, and verify the implementation matches the spec.
A quick self-check before sign-off: can you explain the treatment to a colleague in one sentence without using “it depends”? If the answer requires qualifications, those qualifications are likely hidden treatment versions.
4. Before You Run the Experiment
Before running an experiment, ask two questions:
Can one unit’s treatment affect another unit’s outcome?
Is the treatment precisely defined?
If the answer to either is uncertain, the experiment needs redesign — not a larger sample.
Here is a quick-reference summary of SUTVA violations — what breaks, what it costs, and how to fix it.
Keep Going
Up next: EP8: Identification by Conditioning
With exchangeability (EP5), positivity (EP6), and SUTVA (EP7), we have now covered all three identifiability assumptions. In the next episode, we bring them together — connecting these assumptions to the conditioning strategy that underpins observational causal inference and its link to randomized experiments and A/B testing.
Recommended background (optional)
EP4: The Data You’ll Never See — Understanding Potential Outcomes — SUTVA is a precondition for potential outcomes to be well-defined. EP4 introduces the potential outcomes framework that this post builds on.
EP5: Comparing Apples to Apples — The Exchangeability Assumption — Exchangeability ensures the treated and control groups are comparable. SUTVA ensures the potential outcomes being compared are well-defined.
EP6: No Overlap, No Answer — The Positivity Assumption — Positivity ensures the comparison is possible for every subgroup. Together with exchangeability and SUTVA, these three assumptions enable identification by conditioning.
EP2: The Bridge to Truth — Why Identification Comes Before Estimation — SUTVA is one of the identifiability conditions introduced in EP2. If you want the full picture of what identification requires, EP2 is the foundation.
© 2026 Lin Jia. All rights reserved. This content is created independently on personal time and is based exclusively on public domain academic knowledge. No proprietary, confidential, or employer-owned materials, data, or intellectual property are included. The views and opinions expressed in this work are strictly my own and do not reflect those of any current or former employer. All methodology discussed is sourced from publicly available scientific literature.